
PROBLEM
SOLUTION
IMPACT
KEY DECISIONS

Context
Introduction

Once a week
observed frequency of therapy
3-4 times a week
Optimal frequency of therapy
Identified Solution

Why a 3D Model?

Figure 1. Steps of development for a metahuman character.
Building the Model
Metahuman Creator
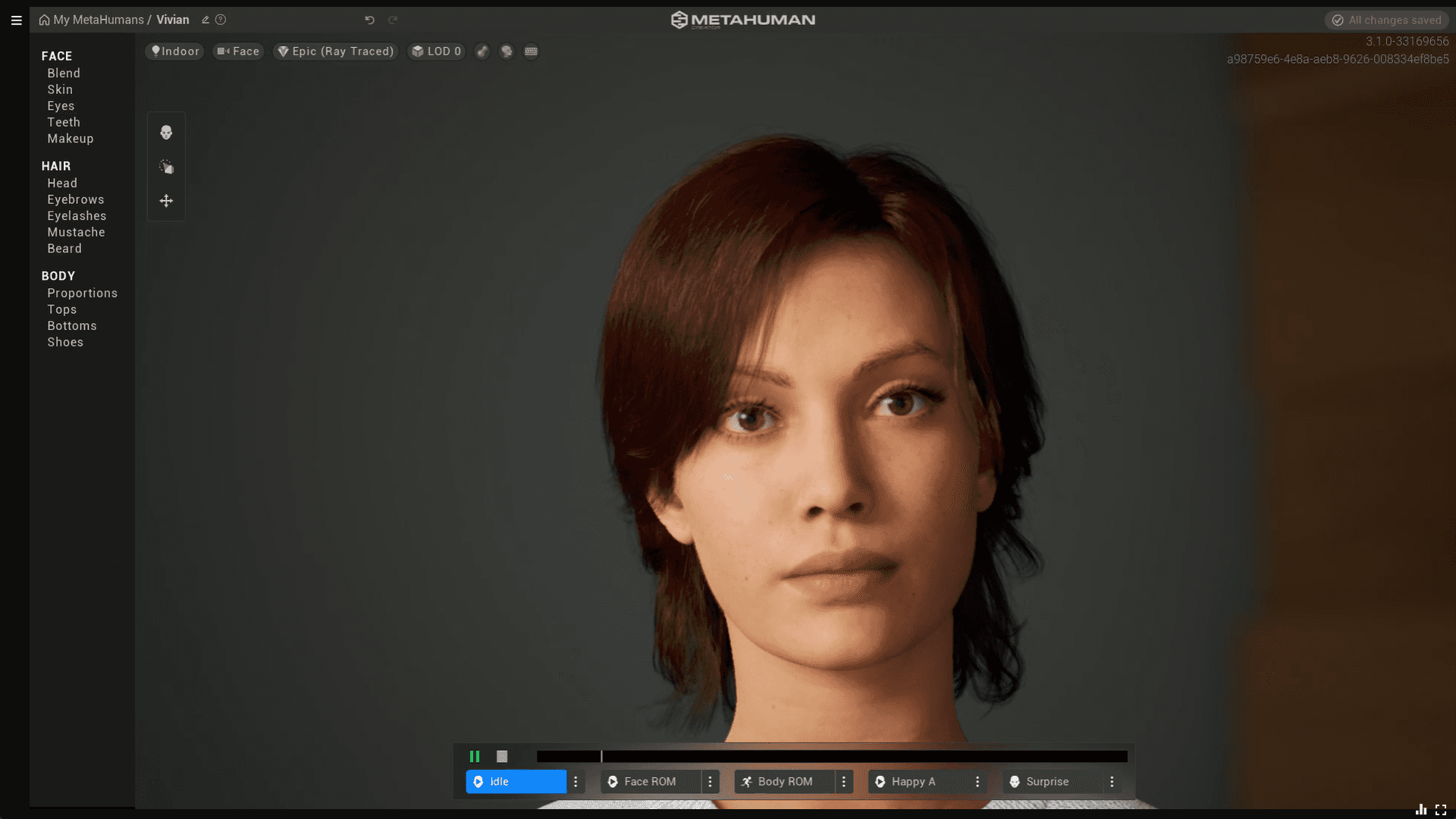
Figure 2. The final iteration of the Metahuman, used for the application - Echo.
Facial Animation
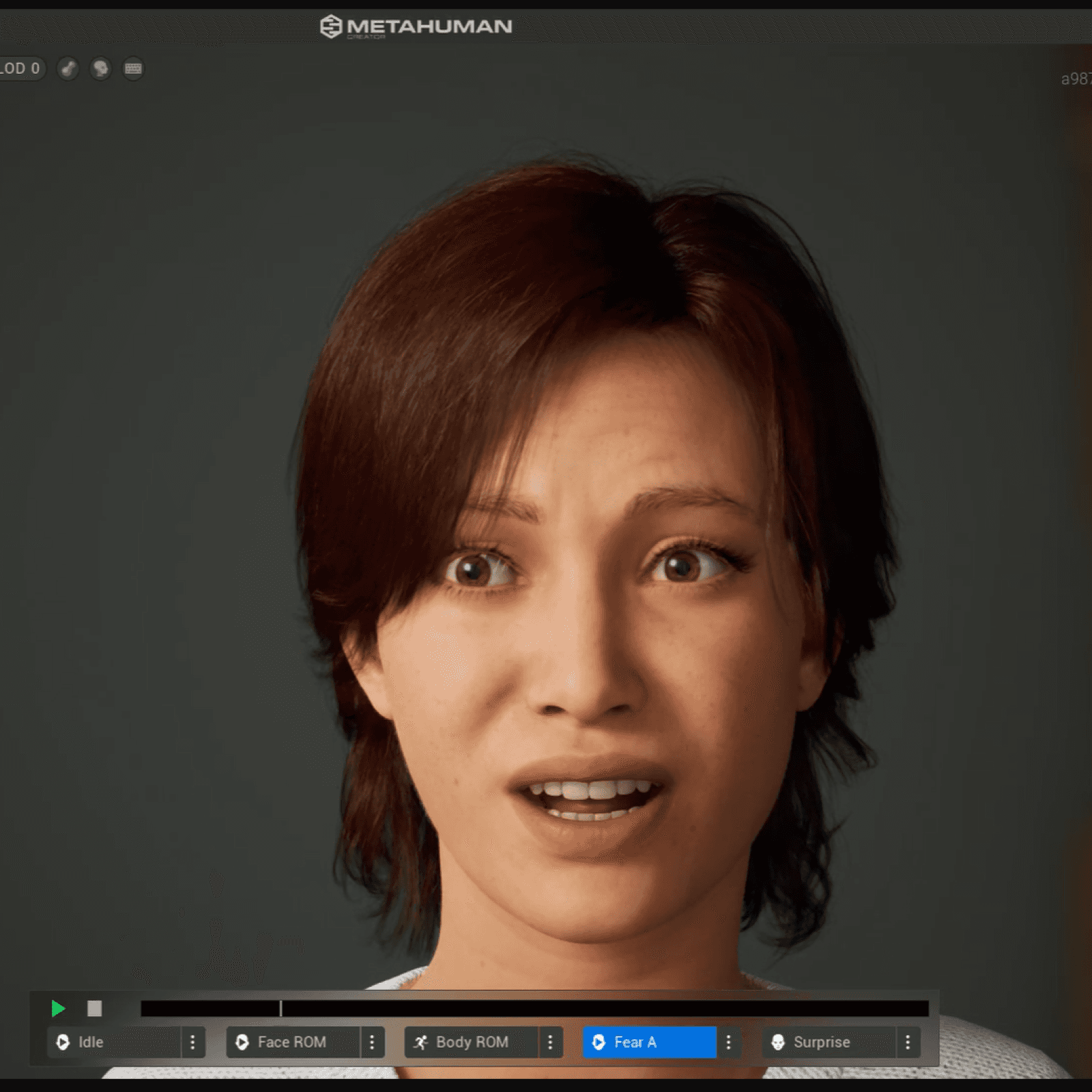
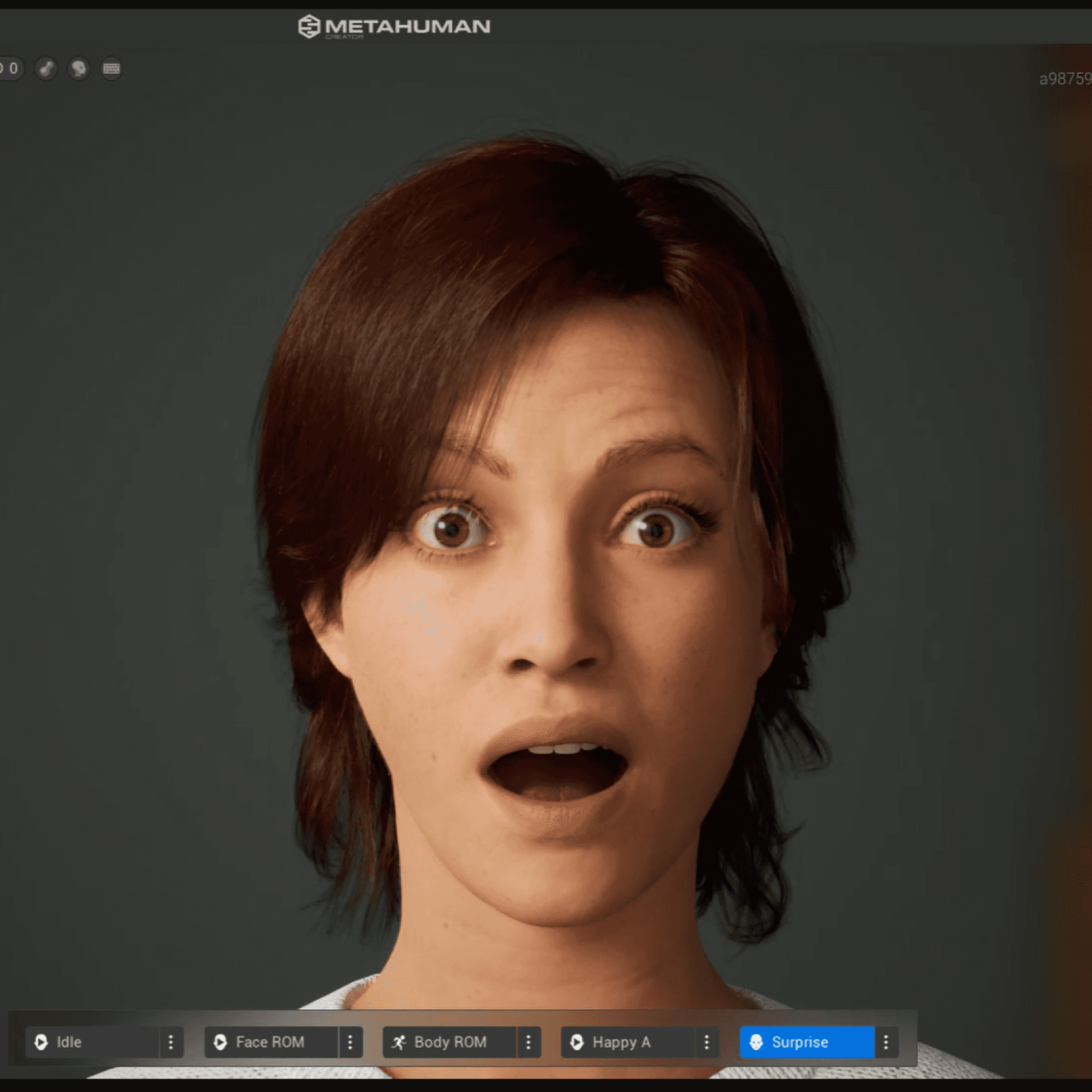
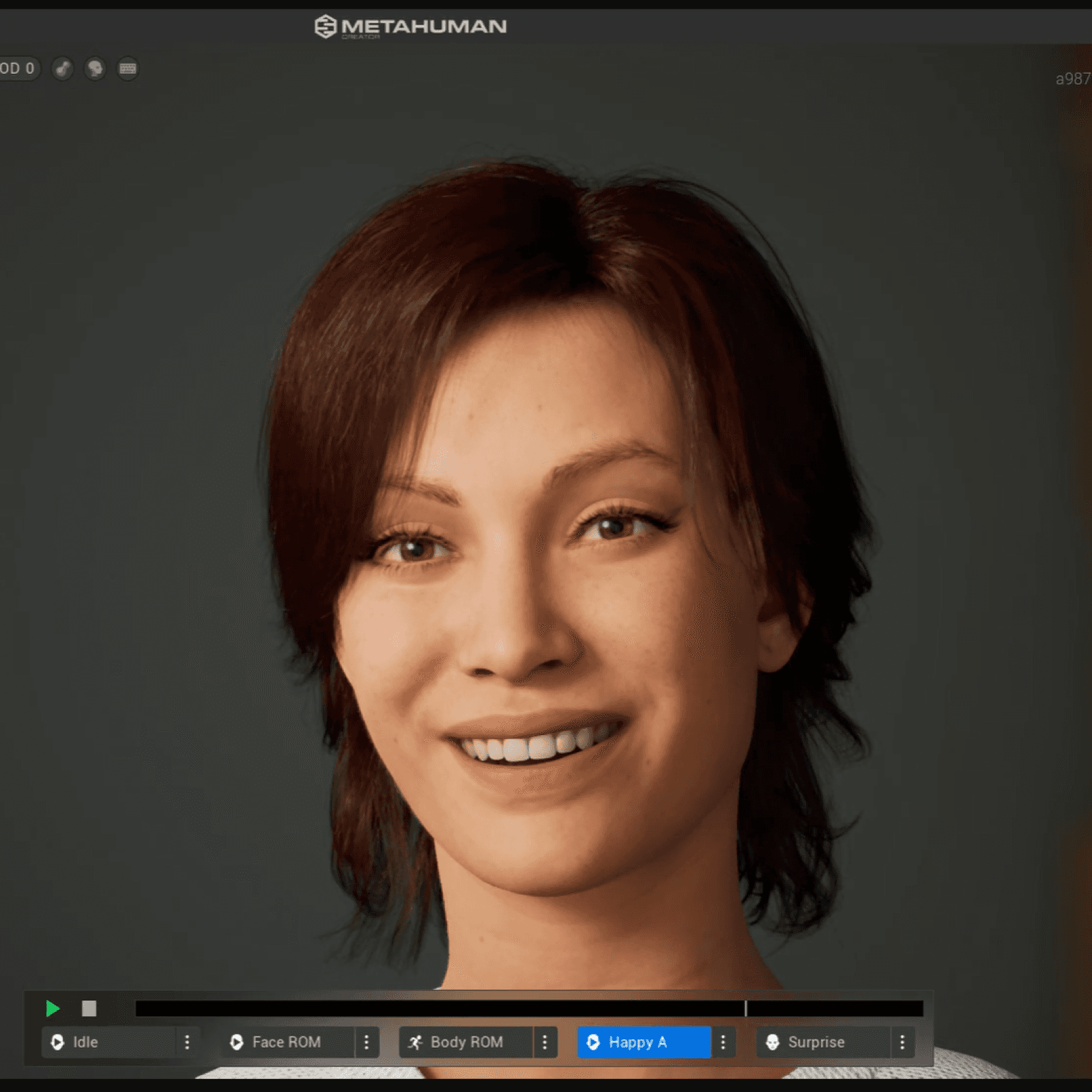
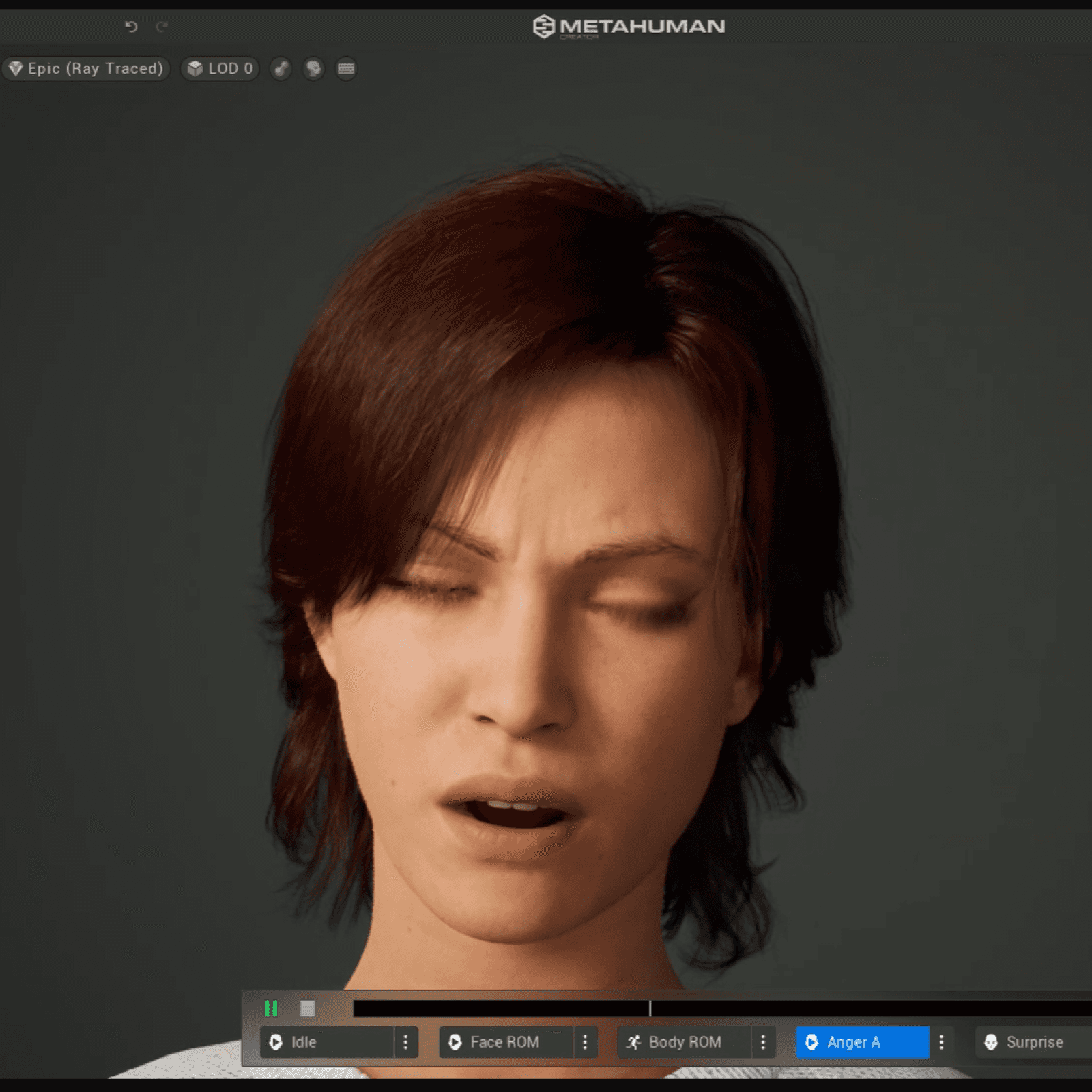
Figure 3. The 3D model displaying different emotions and prosodies.
Voice Integration - NVIDIA Audio2Face

Figure 4. Connecting the 3D model with NVIDIA Audio2Face - based on a TensorRT engine via Live Link
Our Assumptions
Formative Assessment
User Interviews - Phase I

Think-Aloud - Phase II

Participants
3
Adults diagnosed with
Childhood Apraxia of Speech
4
Parents of children diagnosed with
Childhood Apraxia of Speech
Emerging Themes
We observed an increased engagement as evidenced by parent’s feedback, but it was also learned that the animations need some fine-tuning in terms of latency and lip-movement animation - developed by Metahuman Creator.

Results
Transcripts were generated from 4.3 hours of recording to develop codes and their corresponding themes.
What is the impact of integrating a 3D model when delivering therapy for CAS?
The overall reception was positive still some limitations were highlighted by our participants after interacting with the 3D model.

High Engagement!
6 of 7 participants were interested
to learn more.
How does the integration of a 3D avatar facilitate visual cueing, particularly in terms of real-time feedback, such as lip movement synchronization?
Cueing is limited in the current iteration for sounds/words that do not use lip movement to be initiated.
-ch
-sh
Sounds independent of lip movement.
Limitations
-pa
-ma
Sounds with the same lip movements.

Improved animation and visual cueing - an interesting finding!
Even if the engagement factor was significant when using a 3D avatar it might not always translate to effective cueing. The solution will work best for mild to moderate CAS.
High Engagement
Effective Cueing

Revisiting the whiteboard -
Second Iteration
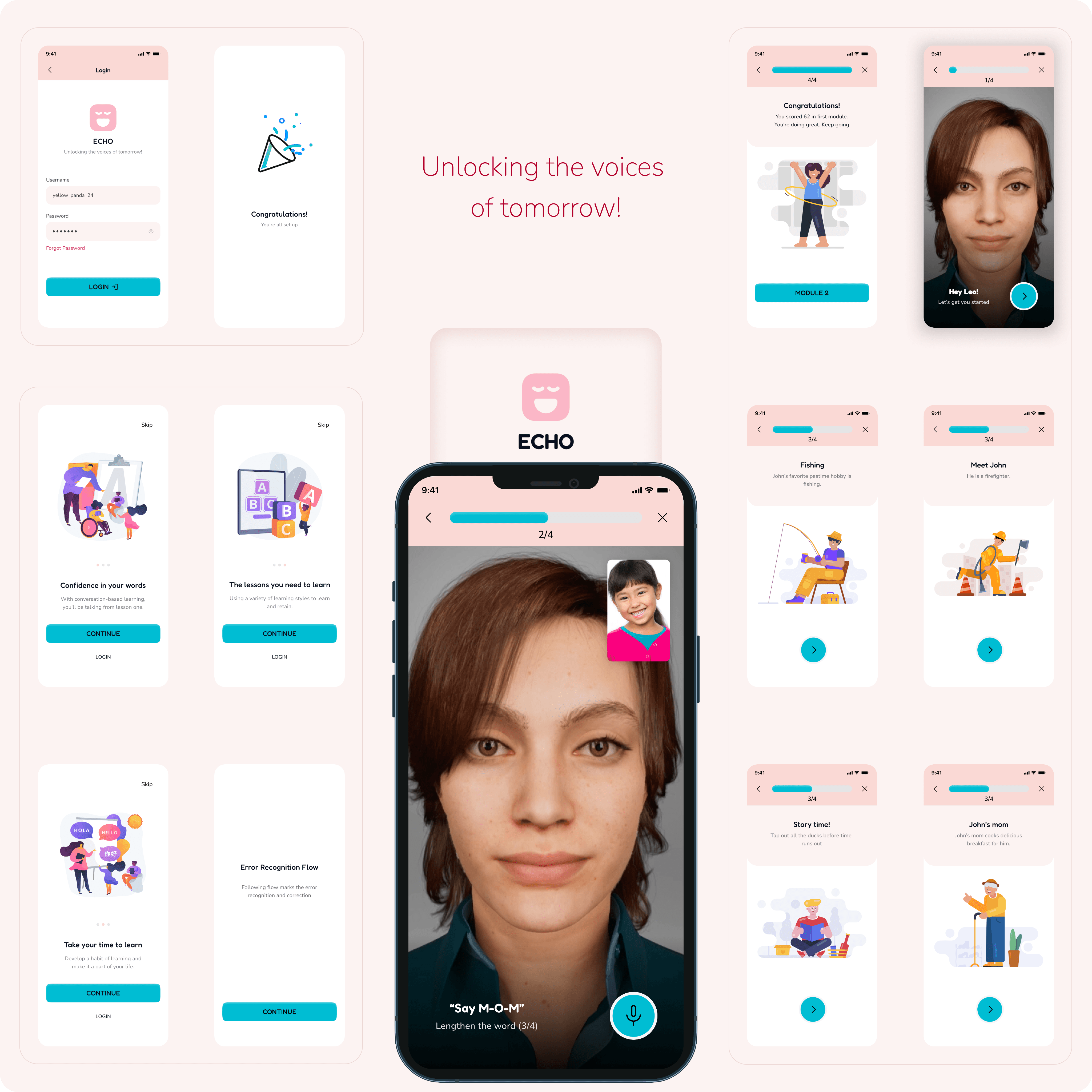
Redesign observes changes in the color palette - making it welcoming towards children. Other changes include storytelling and animations.
Design Directions
Before

2/4


“Say ‘M-O-M’ 4 times”
Follow my cues (2/4)
1
2
3
4
(a)
After
2/4

“Say M-O-M”
Lengthen the word (3/4)
1
2
3
4
(b)
Updated color palette to make the platform friendly and welcoming.
Changed secondary font to Nunito to improve readability and legibility.
Added a mic button to guide users when to start speaking, and move to the next step.
Removed the bottom bar to increase the overall engagement of the application.
Dynamic Storytelling
Storytelling is an effective method to execute the last step of the app-based therapy - spontaneous production (pronunciation at will). As it is better if the word is based on the story, which can be prompted later through a question.



3/4

Meet John
He is a firefighter.
Echo - Style Guide
Color Palette
After the formative assessment, many of our participants highlighted the need of a color palette which is ‘soft’ and ‘easy on the eyes’.
Neutral
Supports secondary colors in background, text and provides hierarchy.
50
#F8FAFC
100
#F1F5F9
200
#E2E8F0
300
#CBD5E1
400
#94A3B8
500
#64748B
600
#475569
700
#334155
800
#1E293B
900
#0F172A
Primary
Used across all interactive elements such as CTA’s, links, active states.
50
#A7F5FF
100
#77F0FF
200
#3AEAFF
300
#1FD5EB
400
#00BDD3
500
#03A9BD
600
#038C9C
700
#046E7A
800
#074249
900
#062C31
Secondary
Used across all interactive elements such as CTA’s, links, active states.
50
#FFF7F6
100
#FCF3F2
200
#FFE4EB
300
#FFC7D4
400
#FBB7C7
500
#FD98B0
600
#FA6E8F
700
#FA5179
800
#D21B46
900
#A00026
Typography
Primary typeface - Fredoka
Fredoka is known for its playful and rounded design, which serves in putting forth a friendly and welcoming nature of the application.
Secondary typeface - Nunito
Nunito is known for its clean and modern design, along with having rounded edges which helps it to integrate well with Fredoka. Nunito has a good x-height increasing its legibility and readability.
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Ii Oo Pp
Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz
1 2 3 4 5 6 7 8 9 0
Fredoka
Aa Bb Cc Dd Ee Ff Gg Hh Ii Jj Kk Ll Mm Ii Oo Pp
Qq Rr Ss Tt Uu Vv Ww Xx Yy Zz
1 2 3 4 5 6 7 8 9 0
Nunito
Iconography
Google material design rounded icons were used to keep a harmony between the fonts and the icons, and to provide a friendly user interface for children.

Motion Graphics
Appropriate animations have been used to engage the users and target their attention towards the call-to-action whenever required.
1/4
Figure 10. Motion design elements of the application.
Future-scope
The future-scope aims to build on the foundations, focusing on the integration of LLM to produce speech along with animating the Metahuman to effectively cue the child.
NVIDIA Nemo - ASR

Figure 11. Pictorial representation of NVIDIA’s Nemo framework.
Due to limited time we were not able to integrate the pre-trained speech recognition model with our 3D avatar, unable to test the random prompt generation. Third iteration will accomplish it enhancing the cueing abilities of the 3D avatar.
Full Body Animation
We plan to make a full body animation of the current model, as it can guide the child through hand gestures making it intuitive for them to understand speech production.
Learnings
The year long study led to many significant discoveries on the remote implementation of speech therapy, leading to the following learnings-
Child-Computer Interaction

Echo, primarily deals with children. I was motivated to learn about the psychology of children and how they perceive digital interfaces.
Conversational Animation

As I integrated the voice animation - lip movement and voice prompts, it led me to understand the nuances of conversational interfaces.
Understanding the Uncanny
still
100%
50%
zombie
prosthetic hand
corpse
human likeness
industrial robot
stuffed animal
healthy
person
uncanny valley
bunraku puppet
humanoid robot
moving
affinity
The integration of the 3D Metahuman instigated the uncanny valley effect. Incorporating subtle animations like blinking, facial muscle movement (brow muscles) ensured the friendliness perception of the 3D Avatar.
